
Los sistemas que tratan el problema de control de concurrencia permiten que sus usuarios asuman que cada una de sus aplicaciones se ejecutan atómicamente, como si no existieran otras aplicaciones ejecutándose concurrentemente.
Esta abstracción de una ejecución atómica y confiable de una aplicación se conoce como una transacción.
Un algoritmo de control de concurrencia asegura que las transacciones se ejecuten atómicamente controlando la intercalación de transacciones concurrentes, para dar la ilusión de que las transacciones se ejecutan serialmente, una después de la otra, sin ninguna intercalación. Las ejecuciones intercaladas cuyos efectos son los mismos que las ejecuciones seriales son denominadas serializables y son correctos ya que soportan la ilusión de la atomicidad de las transacciones.
El concepto principal es el de transacción. Informalmente, una transacción es la ejecución de ciertas instrucciones que accesan a una base de datos compartida. El objetivo del control de concurrencia y recuperación es asegurar que dichas transacciones se ejecuten atómicamente, es decir:
Cada transacción accede a información compartida sin interferir con otras transacciones, y si una transacción termina normalmente, todos sus efectos son permanentes, en caso contrario no tiene afecto alguno.
Una base de datos está en un estado consistente si obedece todas las restricciones de integridad (significa que cuando un registro en una tabla haga referencia a un registro en otra tabla, el registro correspondientes debe existir) definidas sobre ella.
Los cambios de estado ocurren debido a actualizaciones, inserciones y supresiones de información. Por supuesto, se quiere asegurar que la base de datos nunca entre en un estado de inconsistencia.
Sin embargo, durante la ejecución de una transacción, la base de datos puede estar temporalmente en un estado inconsistente.
El punto importante aquí es asegurar que la base de datos regresa a un estado consistente al fin de la ejecución de una transacción.
2007/02/24
TRANSACCIONES
![]()
Suscribirse a:
Enviar comentarios (Atom)

REPRESENTACION DIAGRAMA E-R
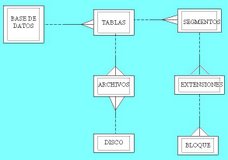
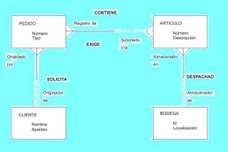
FRASES DE RELACION DE ESTE MODELO E-R
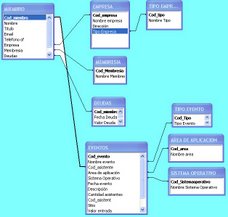
III. DIAGRAMA ENTIDAD - RELACION





















No hay comentarios:
Publicar un comentario